참고문헌
-
https://www.analyticsvidhya.com/blog/2017/09/naive-bayes-explained/
-
책: 밑바닥부터 시작하는 데이터 사이언스
-
http://bcho.tistory.com/1010
-
https://alexn.org/blog/2012/02/09/howto-build-naive-bayes-classifier.html
-
Vijaykumar B, Bayes and Naive-Bayes Classifier
Naive Bayes Classifier from Scratch
<목차>
1.Naive Bayes Classifer란?

1.1 Naive Bayes Classifer 원리
나이브 베이즈 분류기를 간단히 이야기하면 '베이즈 정리를 활용한 분류기'이다. 텍스트 분류나, multi class분류에 쓰인다.
왜 나이브인가? 에 대한 답은 뒤에서 다루겠다.
나이브 베이즈 분류기의 원리를 예를 들어 설명해보겠다.
예) class(c) : spam/ham , : 단어 가 메일에 등장하는가
: 단어 '당첨'이 메일에 등장하는가
1) '당첨'이라는 단어가 나올 때 spam일 확률() 을 알고 싶다고 하면,
-
: 스팸 메일일 때 '당첨'이란 단어가 있을 확률
-
: 전체 데이터에서 스팸 데이터의 확률
-
:
이 세가지와 베이즈 정리를 통해 p(c|x)를 구할 수 있다.
2) 하지만 내가 단순히 '당첨'이라는 단어가 나올때 spam인지 ham인지 "분류"하고 싶은 것이라면,
를 계산하지 않고 만 계산해도 된다.
즉, 과 둘 중 어느 것이 더 큰지만 알고 싶으면,
상단의 식에서 분모 가 동일하므로 를 고려하지 않아도 된다.
3) 우선 구현할 때는 를 살려서 를 구해보겠다...(1)번
1.2 왜 "Naive" 인가? : Conditional Independence
나이브 베이즈 분류기는 강력한 가정을 가지고 있는데,
앞의 예를 들면, 이 스팸 메일에서 '당첨'이란 단어가 나왔다는 사실이, 같은 스팸 메일에서 '로또'란 단어가 나올 것인지에 대해 아무 정보도 주지 않는다는 것이다.
: 단어 '당첨'이 메일에 등장하는가
: 단어 '로또'가 메일에 등장하는가
즉, 이란 가정을 가진다.
이러한 가정 때문에 "Naive"하다고 이름이 붙여졌다.(이런 naive한 가정에도 불구하고 나름 잘 작동한다고 함)
이를 일반화하면,
일 때,
by NAIVE assumption
1.3 Naive Bayes Classifier의 장점과 단점
장점: - class를 쉽고 빠르게 예측한다. - 가정한 독립성이 충족되는 경우 분류기가 더 좋은 성능을 보인다. - 연속형 예측 변수보다, 범주형 예측 변수일 경우에 더 좋은 성능을 보인다.
단점: - zero frequency : 만약 training data set 중 스팸 메일에서 '당첨'이라는 단어가 없었다면, 분류기는 항상 으로 취급하여 '당첨'이라는 단어가 들어가면 무조건 스팸이 아니라고 분류해버린다. 이것을 'Zero Frequency'라고 부르는데, 이것을 해결하는 방법이 'Laplace Smoothing'이다.바로 뒤에서 다루도록 하겠다. - 분류기에서 보여주는 클래스에 대한 확률은 크게 믿을만하지 못하니 분류 결과만 보는게 낫다. (estimation 좋지 않음) - independence에 대한 가정이 비현실적이다.
1.4 Laplace Smoothing
p(x|c) 를 계산할 때 분모와 분자에 임의의 상수 k를 더하는 것이다.
기존에
였다면 Laplace Smoothing은
'당첨'이라는 단어가 들어간 2k개의 메일을 추가적으로 봤다면 k개 스팸 메일, k개의 스팸이 아닌 메일을 봤다고 생각하면 된다.
k=1 또는 0.5를 주로 쓴다,
예를 들어 = 0 / 98 이었다면 k=1일 때 1 + 0 / 2 + 98 = 1/100 = 0.01이다.
1.5 underflow 방지하는 법
underflow란 산술연산의 결과가 컴퓨터가 취급할 수 있는 수의 범위 보다 작아지는 현상을 말한다. 즉, 0에 너무 가까워져 컴퓨터가 표현할 수 있는 영역을 넘어서게 된다.
확률을 여러번 곱하는 과정에서 underflow가 생길 수 있다. 이를 방지하기 위해 exp와 log를 사용한다.
1.6 나올 수 있는 질문
Q: 을 직접 구해도 되는데 왜 를 일일이 곱하나?
A: 추정해야 하는 parameter의 개수가 기하급수적으로 증가하기 때문
만약 가 해당 단어가 나왔다(1), 나오지 않았다(0)로 두 가지 케이스이고 는 spam이다(1), 아니다(0) 두 가지 케이스라면
의 경우 개의 parameter를 필요로 한다.
반면, 는 의 parameter를 필요로 한다.
x variable들의 개수가 늘어날 수록 개의 parameter를 추정하는 것은 어렵게 되므로 naive assumption을 적용하는 것이다.
2. Naive Bayes Classifier 구현
2.1 Naive Bayes 확률 구해보기
구현에 앞서, 쉬운 예로 직접 확률을 구해보자.
class = 13기 준현이가 졸았다/ 안 졸았다
x = 세션주최팀이라고 하자.
다음 데이터는 준현이의 세션 주최팀별 졸았던 기록이다.
내가 알고 싶은 것은
만약 팀세션을 사이언스팀이 주최한다면, 13기 준현이는 졸 것인지!가 궁금한 것이다. (* 예시는 픽션입니다. )
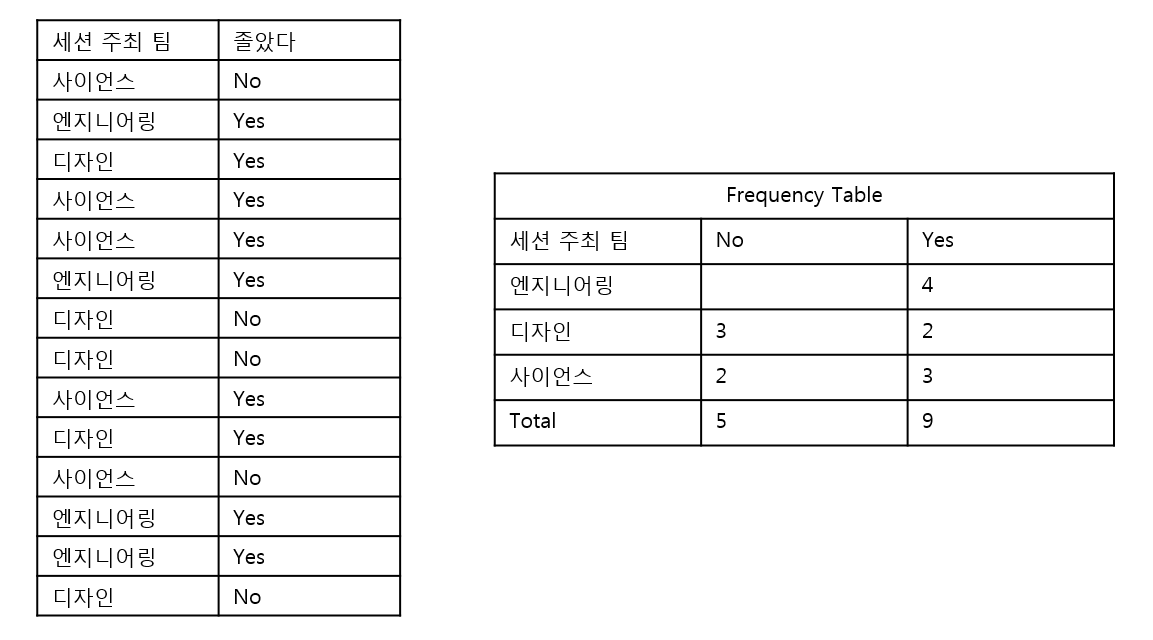
를 구하면 된다.
이므로
이 된다.
반대로
를 구해보면 약 0.4가 나온다.
즉, 만약 팀세션을 사이언스팀이 주최한다면, 13기 준현이는 (슬프게도) 졸 것이다라는 class가 나온다..
여러분 집중 잘하고 있죠.?ㅎㅎㅎ
2.2 Naive Bayes 구현 with python
맨 처음 설명했던 spam, ham인지 분류하는 데이터를 가지고 Naive Bayes Classifer를 만들어봅시다
데이터 셋 출처: https://www.kaggle.com/prafulbhoyar/spam-or-ham-using-nltk
from math import log
from collections import defaultdict
import re
import math
import numpy as np
import random
import pandas as pd
import matplotlib.pyplot as plt
#import nltk
%matplotlib inline
2.2.1 데이터를 불러와서 tuple형태로 바꿔주기
df = pd.read_csv('data/spam.csv',encoding = "ISO-8859-1")
df.dropna(inplace=True,axis=1)
df['is_spam'] = df.v1.map(lambda x: 1 if x =='spam' else 0)
df.head()
subset = df[['v2', 'is_spam']]
tuples = [tuple(x) for x in subset.values]
data = tuples
subset.head() # tuple 형태로 바꾸기 전. v2에는 text, is_spam = 0 이면 ham, 1이면 spam
| v2 | is_spam | |
|---|---|---|
| 0 | Go until jurong point, crazy.. Available only ... | 0 |
| 1 | Ok lar... Joking wif u oni... | 0 |
| 2 | Free entry in 2 a wkly comp to win FA Cup fina... | 1 |
| 3 | U dun say so early hor... U c already then say... | 0 |
| 4 | Nah I don't think he goes to usf, he lives aro... | 0 |
2.2.2 train test split
이 책은 train test split도 구현해놓았다..
def split_data(data, prob):
"""split data into fractions [prob, 1 - prob]"""
results = [], []
for row in data:
results[0 if random.random() < prob else 1].append(row)
return results
random.seed(0) # just so you get the same answers as me
train_data, test_data = split_data(data, 0.75)
2.2.3 token 만들어주는 함수 정의
tokenization 은 간단히 문장을 단어로 쪼개는 것이라고 생각하면 된다.
def tokenize(message):
message = message.lower() # convert to lowercase
all_words = re.findall("[a-z0-9']+", message) # extract the words
return set(all_words) # remove duplicates
2.2.4 word count 함수 정의
단어마다 스팸이었는지 아닌지 담아주는 역할을 한다.
word : [spam_count, non_spam_count]
def count_words(training_set):
"""training set consists of pairs (message, is_spam)"""
counts = defaultdict(lambda: [0, 0])
for message, is_spam in training_set:
for word in tokenize(message):
counts[word][0 if is_spam else 1] += 1
return counts
count_words(train_data)['www']
[79, 2]
count_words(train_data)['latest']
[26, 1]
count_words(train_data)['lol']
[0, 54]
count_words(train_data)['i']
[30, 1229]
2.2.5 확률 계산하기 (word, prob_if_spam, prob_if_not_spam)
prob_if_spam = = '당첨'단어가 들어간 메일 중 스팸의 개수 / 전체 스팸 메일 수 = word count 함수의 spam_count/ total_spams
= word count 함수의 ham_count/ total_non_spams
def word_probabilities(counts, total_spams, total_non_spams, k=0.5):
"""turn the word_counts into a list of triplets
w, p(w | spam) and p(w | ~spam)"""
return [(w,
(spam + k) / (total_spams + 2 * k),
(non_spam + k) / (total_non_spams + 2 * k))
for w, (spam, non_spam) in counts.items()]
2.2.6 확률 log 변환
log 변환에 앞서, 본 책에서 p(spam) = p(~spam) = 0.5라고 가정하여 함수를 짰기 때문에 수정필요
즉, 책에서는 에서 p(c)=p(~c)=0.5 로 가정했기 때문에,
를 이용해 함수를 짰다.
하지만 책과 다른 데이터를 구했으므로 p(c) 와 p(ㄱc)를 0.5라고 가정하기 어렵기에 p(c) 와 p(ㄱc)를 구하여 를 계산한다.
p(c), p(~c) 구하기
prob_spam = df.is_spam.mean() #p(c)
prob_n_spam = 1 - df.is_spam.mean() #p(~c)
log_prob_spam = math.log(df.is_spam.mean())
log_prob_n_spam = math.log(1 - df.is_spam.mean())
prob_n_spam
0.86593682699210339
def spam_probability(word_probs, message):
message_words = tokenize(message)
log_prob_if_spam = log_prob_if_not_spam = 0.0
# iterate through each word in our vocabulary
for word, prob_if_spam, prob_if_not_spam in word_probs:
# if *word* appears in the message,
# add the log probability of seeing it
if word in message_words:
log_prob_if_spam += math.log(prob_if_spam)
log_prob_if_not_spam += math.log(prob_if_not_spam)
# if *word* doesn't appear in the message
# add the log probability of _not_ seeing it
# which is log(1 - probability of seeing it)
else:
log_prob_if_spam += math.log(1.0 - prob_if_spam)
log_prob_if_not_spam += math.log(1.0 - prob_if_not_spam)
prob_if_spam = math.exp(log_prob_if_spam + log_prob_spam)
prob_if_not_spam = math.exp(log_prob_if_not_spam + log_prob_n_spam)
return prob_if_spam / (prob_if_spam + prob_if_not_spam) , prob_if_not_spam / (prob_if_spam + prob_if_not_spam)
#return prob_if_spam, prob_if_not_spam #p(x)제외
2.2.7 Naive Bayes Classifier
class NaiveBayesClassifier:
def __init__(self, k=0.5):
self.k = k
self.word_probs = []
def train(self, training_set):
# count spam and non-spam messages
num_spams = len([is_spam
for message, is_spam in training_set
if is_spam])
num_non_spams = len(training_set) - num_spams
# run training data through our "pipeline"
word_counts = count_words(training_set)
self.word_probs = word_probabilities(word_counts,
num_spams,
num_non_spams,
self.k)
def classify(self, message):
return spam_probability(self.word_probs, message)
2.2.8 Training
classifier = NaiveBayesClassifier()
classifier.train(train_data)
# triplets (subject, actual is_spam, predicted spam probability)
classified = [(subject, is_spam, classifier.classify(subject))
for subject, is_spam in test_data]
len(classified)
1412
classified[5:20] #message, true y, prob(p(spam|x), p(ham|x))
[("Oh k...i'm watching here:)",
0,
(2.1654192519571173e-13, 0.9999999999997834)),
('Eh u remember how 2 spell his name... Yes i did. He v naughty make until i v wet.',
0,
(1.1156061079083015e-12, 0.9999999999988843)),
('Fine if thatåÕs the way u feel. ThatåÕs the way its gota b',
0,
(9.872632576672763e-13, 0.9999999999990127)),
('England v Macedonia - dont miss the goals/team news. Txt ur national team to 87077 eg ENGLAND to 87077 Try:WALES, SCOTLAND 4txt/̼1.20 POBOXox36504W45WQ 16+',
1,
(0.999999999992402, 7.59802372100805e-12)),
('So Ì_ pay first lar... Then when is da stock comin...',
0,
(1.9228965037776113e-13, 0.9999999999998076)),
("I'm back & we're packing the car now, I'll let you know if there's room",
0,
(1.3348419538582625e-15, 0.9999999999999987)),
('Ahhh. Work. I vaguely remember that! What does it feel like? Lol',
0,
(2.2675410918473284e-15, 0.9999999999999978)),
("Yeah he got in at 2 and was v apologetic. n had fallen out and she was actin like spoilt child and he got caught up in that. Till 2! But we won't go there! Not doing too badly cheers. You? ",
0,
(4.947657142390785e-20, 1.0)),
('For fear of fainting with the of all that housework you just did? Quick have a cuppa',
0,
(5.282465874277018e-08, 0.9999999471753412)),
('Anything lor... U decide...',
0,
(7.0520772324458295e-12, 0.9999999999929479)),
('07732584351 - Rodger Burns - MSG = We tried to call you re your reply to our sms for a free nokia mobile + free camcorder. Please call now 08000930705 for delivery tomorrow',
1,
(0.9999999999999949, 5.217598921352504e-15)),
('No calls..messages..missed calls',
0,
(7.194310924784053e-07, 0.9999992805689075)),
("U don't know how stubborn I am. I didn't even want to go to the hospital. I kept telling Mark I'm not a weak sucker. Hospitals are for weak suckers.",
0,
(1.5488309997938528e-12, 0.9999999999984511)),
('What you thinked about me. First time you saw me in class.',
0,
(2.4280391486778872e-12, 0.9999999999975719)),
('Do you know what Mallika Sherawat did yesterday? Find out now @ <URL>',
0,
(1.6946786171582476e-12, 0.9999999999983054))]
p(x)를 빼고 확률을 계산해도 잘 분류할까?
classified[5:20] #message, true y, prob(p(x|spam)p(spam), p(x|ham)p(ham))
[("Oh k...i'm watching here:)",
0,
(6.586403265399219e-28, 3.04162958717808e-15)),
('Eh u remember how 2 spell his name... Yes i did. He v naughty make until i v wet.',
0,
(8.914971224846361e-52, 7.991145944469131e-40)),
('Fine if thatåÕs the way u feel. ThatåÕs the way its gota b',
0,
(1.6866576840858246e-33, 1.7084173557409857e-21)),
('England v Macedonia - dont miss the goals/team news. Txt ur national team to 87077 eg ENGLAND to 87077 Try:WALES, SCOTLAND 4txt/̼1.20 POBOXox36504W45WQ 16+',
1,
(6.4749473707174035e-52, 4.919680371536333e-63)),
('So Ì_ pay first lar... Then when is da stock comin...',
0,
(8.510414665944486e-38, 4.425830849046623e-25)),
("I'm back & we're packing the car now, I'll let you know if there's room",
0,
(2.035431749701e-43, 1.5248484989685343e-28)),
('Ahhh. Work. I vaguely remember that! What does it feel like? Lol',
0,
(1.9644459667901295e-36, 8.663331279212776e-22)),
("Yeah he got in at 2 and was v apologetic. n had fallen out and she was actin like spoilt child and he got caught up in that. Till 2! But we won't go there! Not doing too badly cheers. You? ",
0,
(4.643704490224721e-69, 9.3856634697626e-50)),
('For fear of fainting with the of all that housework you just did? Quick have a cuppa',
0,
(1.0160649499325768e-31, 1.9234670330896473e-24)),
('Anything lor... U decide...',
0,
(4.186078025607638e-25, 5.935950341437603e-14)),
('07732584351 - Rodger Burns - MSG = We tried to call you re your reply to our sms for a free nokia mobile + free camcorder. Please call now 08000930705 for delivery tomorrow',
1,
(3.4202726396135594e-39, 1.784561083517928e-53)),
('No calls..messages..missed calls',
0,
(4.843379992980226e-22, 6.73223128544093e-16)),
("U don't know how stubborn I am. I didn't even want to go to the hospital. I kept telling Mark I'm not a weak sucker. Hospitals are for weak suckers.",
0,
(1.3008490358365658e-55, 8.398908828708181e-44)),
('What you thinked about me. First time you saw me in class.',
0,
(3.8474132507480484e-31, 1.5845762836376402e-19)),
('Do you know what Mallika Sherawat did yesterday? Find out now @ <URL>',
0,
(4.184971038778113e-37, 2.469477691167583e-25))]
#추가내용 from 동영
##########train voca와 그에따른 conditional확률을 갖고 있는 word_probs만들기
training_set=train_data
num_spams = len([is_spam
for message, is_spam in training_set #training set은 (mail내용, spam인지)로 구성되어 있다
if is_spam])#그냥 총 spam인 갯수 세는것
num_non_spams = len(training_set) - num_spams
# run training data through our "pipeline"
word_counts = count_words(training_set)
word_probs = word_probabilities(word_counts,
num_spams,
num_non_spams,
0.5)
##########함수선언. exp(sum(log))안하고 직관적으로 보일수잇게 그냥 cum product함. traindata는 크지 않아서 자릿수문제 없엇음(결과 완전 같음)
def spam_probability_v3(word_probs, message,prin=False):
if prin:
print('start_word_prob_sum...')
message_words = tokenize(message)
log_prob_if_spam = log_prob_if_not_spam = 1
# iterate through each word in our vocabulary
for word, prob_if_spam, prob_if_not_spam in word_probs:
# if *word* appears in the message,
# add the log probability of seeing it
if word in message_words:
if prin:
print("""\'%s\' is in inputword,
prob=%s*%s and not_prob=%s*%s"""%(word,log_prob_if_spam,(prob_if_spam),log_prob_if_not_spam,(prob_if_not_spam)))
log_prob_if_spam *= (prob_if_spam)
log_prob_if_not_spam *= (prob_if_not_spam)
# if *word* doesn't appear in the message
# add the log probability of _not_ seeing it
# which is log(1 - probability of seeing it)
else:
if prin:
'''print("""\'%s\' is NOTIN inputword,
prob=%s*%s and not_prob=%s*%s"""%(word,log_prob_if_spam,math.log(1.0 - prob_if_spam),log_prob_if_not_spam,math.log(1.0 - prob_if_not_spam)))'''
log_prob_if_spam *=(1.0 - prob_if_spam)
log_prob_if_not_spam *=(1.0 - prob_if_not_spam)
prob_if_spam = log_prob_if_spam #+ log_prob_spam) #수정함
prob_if_not_spam = log_prob_if_not_spam # + log_prob_n_spam) #수정함
if prin:
print('final spamprob:%s, not_spam_prob:%s, return_value:%s'%(prob_if_spam,prob_if_not_spam,(prob_if_spam / (prob_if_spam + prob_if_not_spam))))
return prob_if_spam / (prob_if_spam + prob_if_not_spam)
class NaiveBayesClassifier_v3:
def __init__(self, k=0.5):
self.k = k
self.word_probs = []
def train(self, training_set):
# count spam and non-spam messages
num_spams = len([is_spam
for message, is_spam in training_set
if is_spam])
num_non_spams = len(training_set) - num_spams
# run training data through our "pipeline"
word_counts = count_words(training_set)
self.word_probs = word_probabilities(word_counts,
num_spams,
num_non_spams,
self.k)
def classify(self, message,prin=False):
return spam_probability_v3(self.word_probs, message,prin=prin)
##########train voca에 있는 것중 0번째,1번째,100번째 단어가 들어간 phrase로 classifier에 돌려봄.
#확률이 cumprod되는것도 알 수 있고, 100번째 단어는 2번째단어~99번째 단어들의 false확률이 곱해짐을 알 수 있다.
classifier_v3 = NaiveBayesClassifier_v3()
classifier_v3.train(train_data)
test_phrase='%s %s %s'%(word_probs[0][0],word_probs[1][0],word_probs[100][0])
print(test_phrase)
my_test=(test_phrase,1)
(my_test[0], my_test[1], classifier_v3.classify(my_test[0],prin=True))
########이건 그냥 함수의 특성확인.
#train data에 없는 애는 그냥 무시해버린다, 같은 단어가 몇개나오던 신경안쓴다(실제 classifier도 이렇게 짜여져잇나?)
"""test_phrase='haeju is A graduate student in A applied statistics...'
print(test_phrase)
my_test=(test_phrase,1)
(my_test[0], my_test[1], classifier_v3.classify(my_test[0],prin=True)) """
08452810075over18's t reward
start_word_prob_sum...
'08452810075over18's' is in inputword,
prob=1*0.004370629370629371 and not_prob=1*0.0001392757660167131
't' is in inputword,
prob=0.004370629370629371*0.08828671328671328 and not_prob=0.0001392757660167131*0.005431754874651811
'reward' is in inputword,
prob=9.836262467427133e-07*0.011363636363636364 and not_prob=3.514099196746553e-08*0.0001392757660167131
final spamprob:1.0688487273188048e-19, not_spam_prob:5.3801212413105225e-17, return_value:0.0019827238970269055
"test_phrase='haeju is A graduate student in A applied statistics...'\nprint(test_phrase)\nmy_test=(test_phrase,1)\n\n(my_test[0], my_test[1], classifier_v3.classify(my_test[0],prin=True)) "